Local Models, Unified Memory, and Why Quantization Matters
Why this showed up on my machine
I have been exploring running large language models, specifically Qwen3.6 9B, alongside inference stacks like Ollama and llama.cpp-style runners, single sequence, no batching. I’ve also been digging into SGLang to understand inference fundamentals. The part that always snaps me back to reality is not the model card, it is RAM. For reference, I have a Mac M4 Air with 16 gigs of RAM, gets the work done for a lot of parallel coding tasks, but hits a ceiling when I have to run local models.
Again, that is enough to do real work, but not enough to pretend I am on a server with VRAM that is only for the GPU. Apple Silicon uses unified memory: the same physical DRAM backs CPU work, GPU style work, and the Apple Neural Engine when a runtime routes ops there. The diagram below is the mental model I keep in mind before I pick a context length or a GGUF quant (GGUF is just a file format for quantised models, more on it later.).
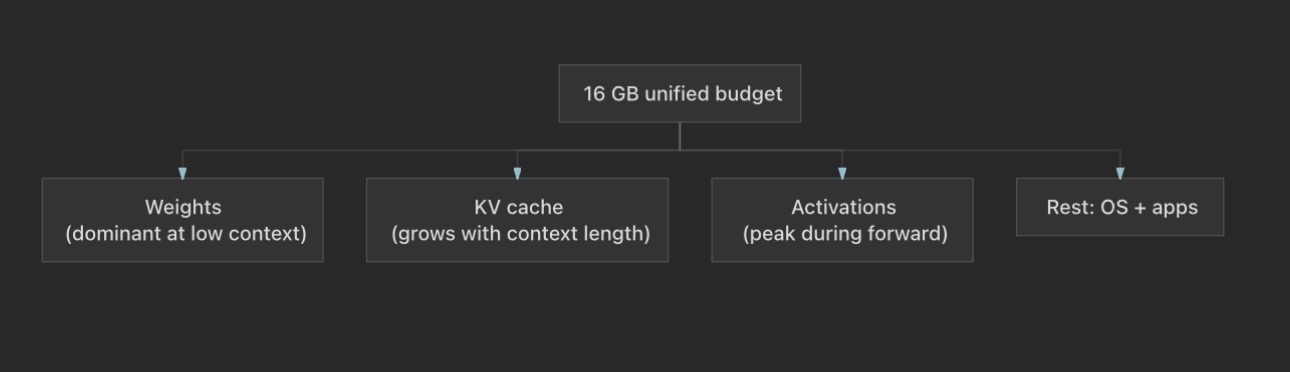
Anything the OS, browsers, IDEs, and background apps hold in RAM is not available for weights, KV cache, or large activation buffers. In practice I watch headroom the same way I watch disk: if I am near the limit, the system starts compressing pages or spilling to swap, and inference latency becomes noisy. So the planning question is always: how many billions of parameters can I keep resident, at what effective width, and how long a context can I afford before KV cache eats the remainder?
What dominates memory for a ~7B model (rough mental model)
I’ll use 7B as the anchor for the math since it’s the most common reference point; scale linearly for 9B.
For a 7B parameter model, the headline numbers depend mainly on three things:
-
Weights: count × bytes per parameter (dtype / packing). A useful anchor is FP16 or BF16 at two bytes per parameter: GB before KV, activations, and the OS. That is already tight on a 16 GB machine, which is why people rarely run full BF16 7B with long context and a heavy desktop at the same time.
-
KV cache: scales linearly with sequence length . For one typical layout (batch size 1):
where is the number of layers, the number of KV heads (after GQA), the head dimension, the sequence length (prompt + generated tokens you keep), and bytes per element in the cache dtype. The leading is for K and V. Grouped query attention (GQA) shrinks relative to the attention head count, which is one reason modern 7B models are more usable on laptops than an old multi head attention (MHA) stack at the same parameter count. Multiply by batch size if .
-
Activations: intermediate feature maps during inference. They matter for peak memory during a forward pass and for throughput tricks like batching, even when weights dominate the story at batch size 1 and modest .
The sketch below is the same idea as the formulas, but as one budget you partition, not four separate VRAM pools.
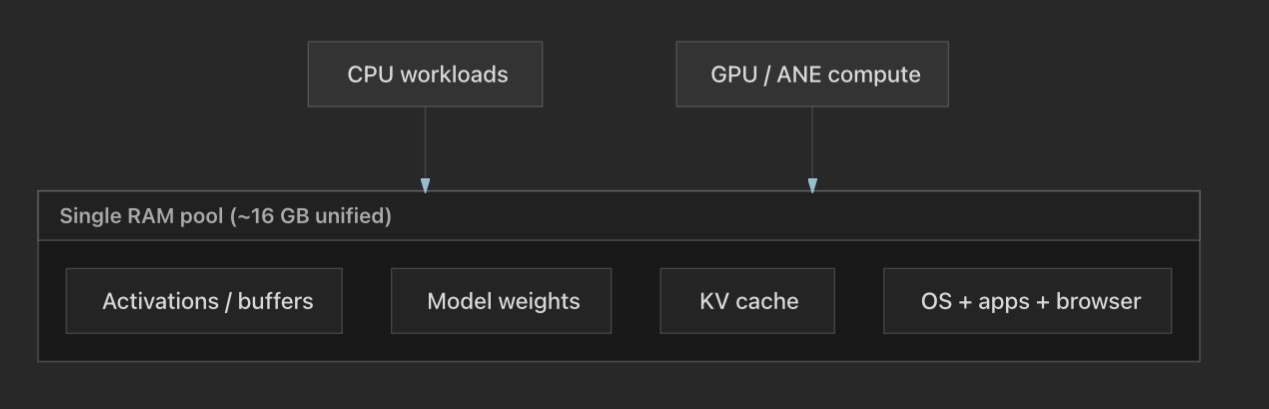
A concrete back of the envelope
Qwen2.5 Coder 7B in FP32 is about:
for weights alone, before KV cache, runtime buffers, and the rest of the system. That already explains why FP32 full weights on a 16 GB unified machine is not practical; you lean on smaller dtypes (FP16, BF16, sometimes INT8 for weights in some stacks) and quantized on disk formats such as GGUF with 2 to 5 bit style encodings for the bulk of the tensor data.
Legacy (affine) quantization
A floating tensor is mapped to integers in using a scale and often a zero point . A common affine dequantization is:
where is the stored integer. Equivalently, quantization uses the inverse mapping (with rounding and clipping):
Given a real range on a slice of weights, classical per tensor scales are derived so that the integer range spans that interval, for example:
(then may be adjusted after clipping into valid integer range). Implementations differ in details (symmetric clipping, per channel vs per tensor, etc.), but the story is always compress with integers, recover with and .
Symmetric vs asymmetric (int8 flavor)
Symmetric (e.g. signed int8, zero point fixed at 0)
You store something like and reconstruct . The zero point needs no storage (), so per group you typically only publish a scale, with less metadata per weight when amortized over the block. Calibration is simpler and dequant is slightly cheaper. You give up some dynamic range flexibility if the tensor is not centered at zero.
Asymmetric (e.g. uint8 style range with learned or computed )
You allow so the quantized grid can align better with shifted tensors. Often better reconstruction for the same integer width per stored weight on skewed distributions. The stored weights are still the same nominal width as symmetric (e.g. 8 bits), but you usually carry more metadata per scaling group, both a scale and a zero point, whereas symmetric can fix and only ship the scale. If you amortize metadata + payload over the weights in that group, asymmetric has a slightly higher effective bits per weight; the trade off is paying that overhead for a grid that fits the tensor better.
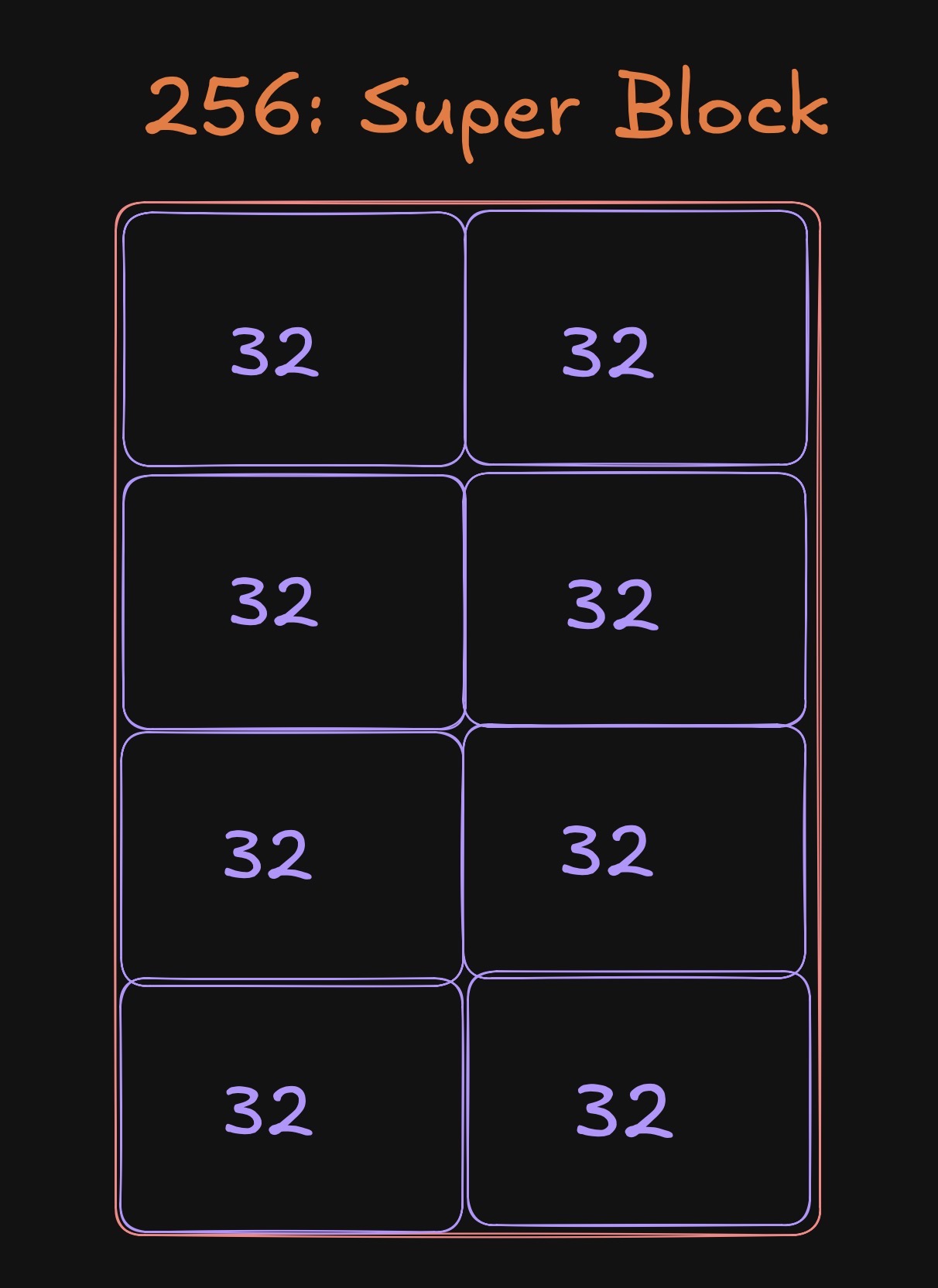
K quants (GGUF / llama.cpp family)
K quants are still scalar quantization at the weight level, but they use a hierarchy of block scales: a super block carries coarse scale (and related metadata), and finer sub blocks refine it. That lets low bit formats keep error bounded better than a single global scale.
In the llama.cpp family it is common to see a 256 weight super block built from eight groups of 32 weights. Each group can carry finer scale information, while the super block shares coarser terms. The picture is only geometry, not a spec sheet, but it matches how I think about why K quants track error more locally than one scale for the whole tensor.
You will see suffixes like _S, _M, _L on types such as Q4_K_* and Q5_K_*:
_S(small): more aggressive grouping; smaller metadata overhead, often a bit leaner on disk and RAM._M(medium): a common default trade off between size and quality._L(large): tends toward higher fidelity within the same nominal bit width by using coarser super blocks with more expressive per block parameters.
Exact behavior is implementation specific; when choosing a file, the practical move is to compare perplexity or your own task evals on two candidates at similar size. For me, I just always go with M based quants, the size and quality is almost perfect for the stuff that I want locally from a model
I quants (“IQ” family)
This line is closer to vector quantization: weights are grouped into vectors that index codebooks (shared lookup tables of representative vectors), sometimes mixed with a few high precision outliers or importance hints. An importance matrix (or related heuristic) can allocate more precision to columns or channels that matter more for output quality.
The upside is very low average bits per weight when memory is the binding constraint. The downside is more complex kernels: you may save disk and RAM yet pay in decode cost or kernel coverage on some backends, and very small codebooks can hit quality cliffs on hard layers.
If you have serious memory limits, use I quant version of models but with importance matrix, The idea/concept behind I quants is very intriguing and deserves its own post, for now I’ll leave it like this.
TL;DR
- On a 16 GB unified memory Mac, treat RAM as one budget for weights, KV cache, activations, and the OS. Unified memory is a strength for bandwidth, not a magic duplicate of “GPU RAM plus CPU RAM.”
- Affine / “legacy” quants = scale + optional zero point; symmetric is simpler, asymmetric often uses the same bit width more flexibly at the cost of more metadata per group.
- K quants = block wise scales with super blocks;
Q4_K_M/Q5_K_M(and neighbors) are practical defaults when you want noticeably smaller models without giving up as much quality as the most aggressive formats. - I quants = codebook / vector quant ideas + importance, best when memory is the serious bottleneck and you are willing to lean on heavier compression.
If you are picking a GGUF for day to day coding assistance on limited RAM, start around Q4_K_M or Q5_K_M, then step up or down based on whether quality or headroom matters more.
hope you enjoyed reading this as much as I enjoyed writing about this :)